



How Our team Built a RAG-Powered Lead Agent for Our Company Website in a Day
From a Cold Contact Form to a Conversational Assistant
When I recently revamped our company website — giving it a fresh theme, updated service pages, and a sleek project portfolio (You can read about how I used Claude for the same here) — I paused for a moment at the “Contact Us” section.
There it was again: the same old Contact Form 7 widget, silently waiting for visitors to type their name, email, and a vague message.
And it hit me — why would anyone leave a query on such a cold, lifeless form?
That’s when the idea clicked.
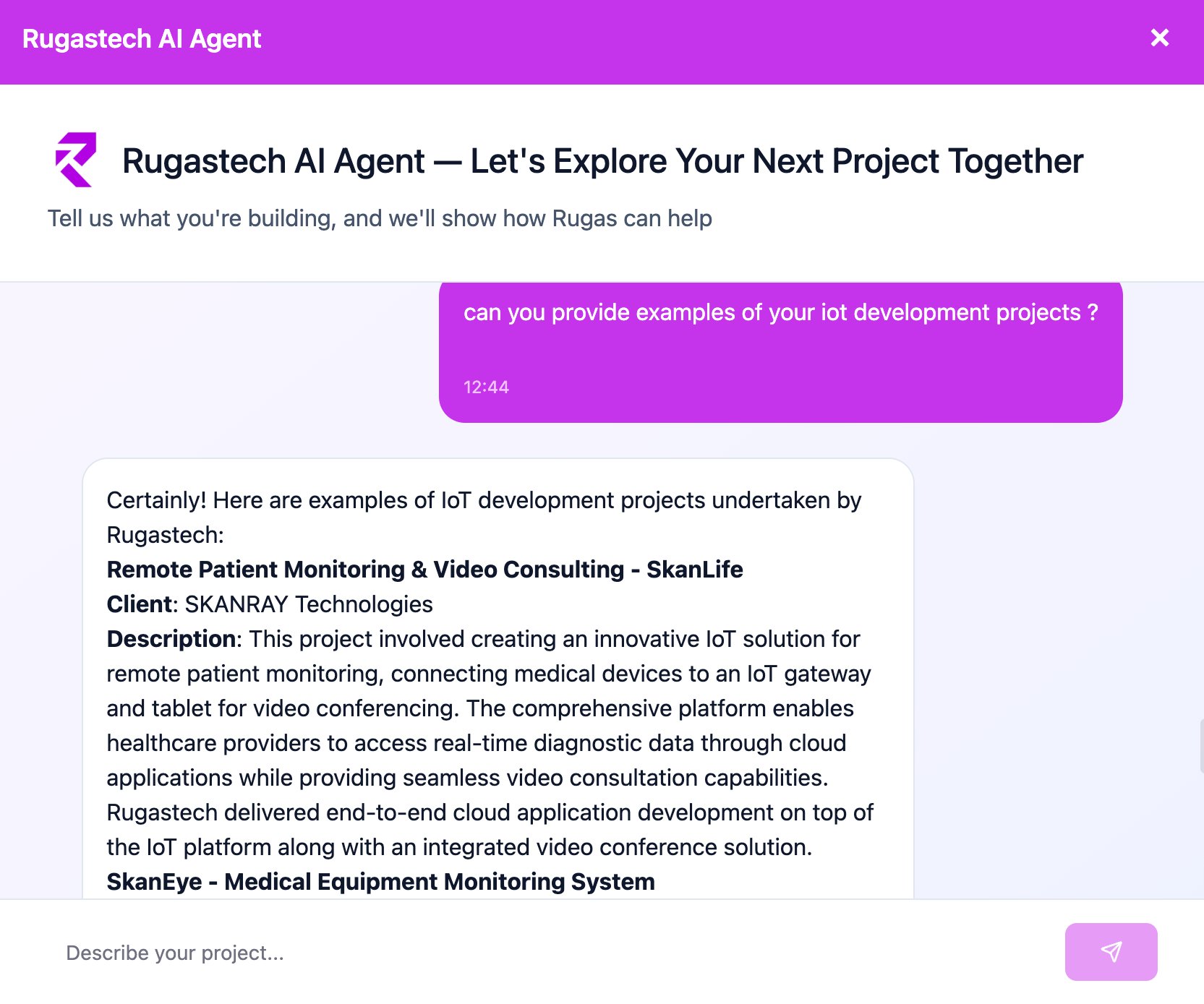
What if, instead of a static form, visitors could talk to an assistant — one that actually understood our services, our project experience, and our clientele?
An assistant that could ask smart follow-up questions, understand what the visitor is trying to build, and even explain how our services could help — before finally collecting their details naturally, as part of a conversation.
So, I decided to build one — a RAG-powered AI assistant that could live right on our website and do all this.
And the fun part? We took it as a challenge to build it in a single day !
Getting into Action — Choosing the Right Stack
Once the idea was clear in my head, I jumped straight into figuring out how to build it quickly — something that would work end-to-end without over-engineering.
After a short round of brainstorming with the team (and some coffee), We settled on a lightweight, pragmatic stack:
- FAST API — to handle user queries, both streaming (for real-time chat) and non-streaming responses.
- React — for building a simple, elegant chat widget that could be easily embedded into our website.
- SQLite — a no-fuss database to store incoming leads directly from the conversations.
- Chroma DB — as the vector store, to hold all our knowledge base documents — services, project case studies, client profiles, and more.
The idea was to keep it modular yet fast to prototype — one that I could evolve later into a production-grade AI assistant, but first, just get something working today.
Feeding the Brain — Building the Knowledge Base
With the framework ready, it was time to give our chatbot some brains.
We needed a way to make it aware of our services, projects, and client success stories — so that it could confidently talk about what we do and how we help.
To start, our Backend Engineer quickly wrote two utility methods:
1. A function to create embeddings from any text document.
self.model = OpenAI(api_key=settings.openai_api_key)
def generate_embedding(self, text: str) -> List[float]:
response = self.model.embeddings.create(
model=self.model_name,
input=text
)
return response.data[0].embedding
2. Another to store those embeddings into our Chroma DB vector store.
For simplicity, we chose OpenAI embeddings — not because we did a cost-performance benchmark, but because they were easy, reliable, and fast enough to get things moving.
Then came the structure. we defined a few clean JSON templates — one for our services, another for projects.
Each JSON captured essential context like:
Service name, description, and technologies used.
Project title, client domain, problem solved, and results achieved.
Once filled, I fed these documents into our embedding utility — and watched as they were transformed into vector representations and neatly stored inside Chroma DB.
Also added a logic to calculate similarity score based on the distances of the results and returing only those results which are above a similarity score threshold.
In just a couple of hours, our assistant had a memory — a vectorized understanding of everything Rugas Technologies had built. Then we also wrote a quick search function into our collection to fetch relevant content for the query.
Wiring It Up — APIs, Streaming, and RAG in Action
Once the knowledge base was in place, it was time to bring the assistant to life.
Again our backend engineer quickly built a set of lightweight FastAPI endpoints that connected everything together — the frontend chat, vector store, and LLM.
The core idea was simple:
Whenever a user asked a question, we first queried ChromaDB using embeddings to fetch the most relevant chunks of context.
These snippets were then combined with the user’s query and passed to the OpenAI LLM for generating responses — classic RAG (Retrieval-Augmented Generation).
To make the experience conversational and natural, we enabled streaming responses.
So instead of waiting for the entire answer, users could see the reply unfold in real time — much like chatting with a real person.
Finally, we added a quick SQLite-based logging system to store the entire conversation history.
This allowed us to feed previous exchanges back to the model, giving it the full context of the conversation.
It also meant we could later analyze user queries or even re-train on recurring themes.
Giving the Assistant a Tool — Smart Lead Capture
One of the most satisfying parts of the build was when the chatbot stopped being just a “talker” and started doing real work.
We wanted the assistant to automatically capture lead information — name, email, company, and project idea — as it appeared naturally in the conversation.
So instead of exposing any external API, we built a simple internal CRUD utility — a neat Python layer built on top of Pydantic models, directly working with the SQLite database.
This allowed the assistant to safely create or update lead records during a conversation, without any external calls.
Here’s how it worked:
When a visitor mentioned something like “We’re building an appointment scheduling app for our dental chain,”
the assistant intelligently extracted key details such as the project idea or organization name.
It then politely asked:
“Would you mind sharing your email or phone number so our team can reach out with more details or understand your project better?”
Once the user shared those details, the assistant used the internal CRUD function to store or update the lead information.
That was the moment the chatbot truly came alive — not just answering questions about our capabilities, but quietly building a qualified lead list as it chatted, ready for our sales and project teams to follow up.
Bringing It to Life — The React Chat Widget
Once the backend and RAG pipeline were working, it was time to bring the chatbot to life — and that’s where the rest of the team jumped in.
Our frontend engineer built a clean, single-page React app that connected to the streaming FastAPI endpoint.
It rendered each token in real time through a Markdown renderer, making the responses flow naturally on screen. They even added a subtle “Thinking…” animation while the bot processed a query — a small touch that gave the interaction personality.
Meanwhile, our DevOps engineer took care of the deployment side — wrapping the React app into a lightweight widget script that could be embedded as an <iframe> inside our WordPress site, and hosting the backend on a DigitalOcean VM. You can see it live at https://rugastech.com
By the end of the day, the entire pipeline — from the knowledge base and streaming APIs to the chat UI and deployment — was live and functional.
From a static contact form to a fully conversational AI assistant, our website now greeted visitors with intelligence and warmth.
Wrapping Up — Small Build, Big Potential
What began as a quick idea turned into a 24-hour team sprint — and the results were incredible.
With our backend engineer wiring up the FastAPI endpoints and database,
our frontend engineer crafting the React chat widget with streaming responses, and our DevOps engineer spinning up a clean DigitalOcean deployment, we had the entire chatbot live and talking to users within a day.
The current setup runs smoothly on ChromaDB, but we’ve already discussed how it can scale to Milvus or other distributed vector stores as our knowledge base expands.
Future plans include automatic document ingestion — PDFs, web pages, structured JSONs — to continuously enrich the assistant’s understanding.
We also see exciting possibilities with automation tools like n8n, to trigger email responses or CRM updates the moment a lead is captured.
It’s amazing how a simple idea — replacing a cold contact form with a conversational assistant — turned into a cross-functional collaboration that delivered a working, scalable, and intelligent system in record time.
And for us, this feels like just the beginning.