LLM Fine-tuning & Classification Training
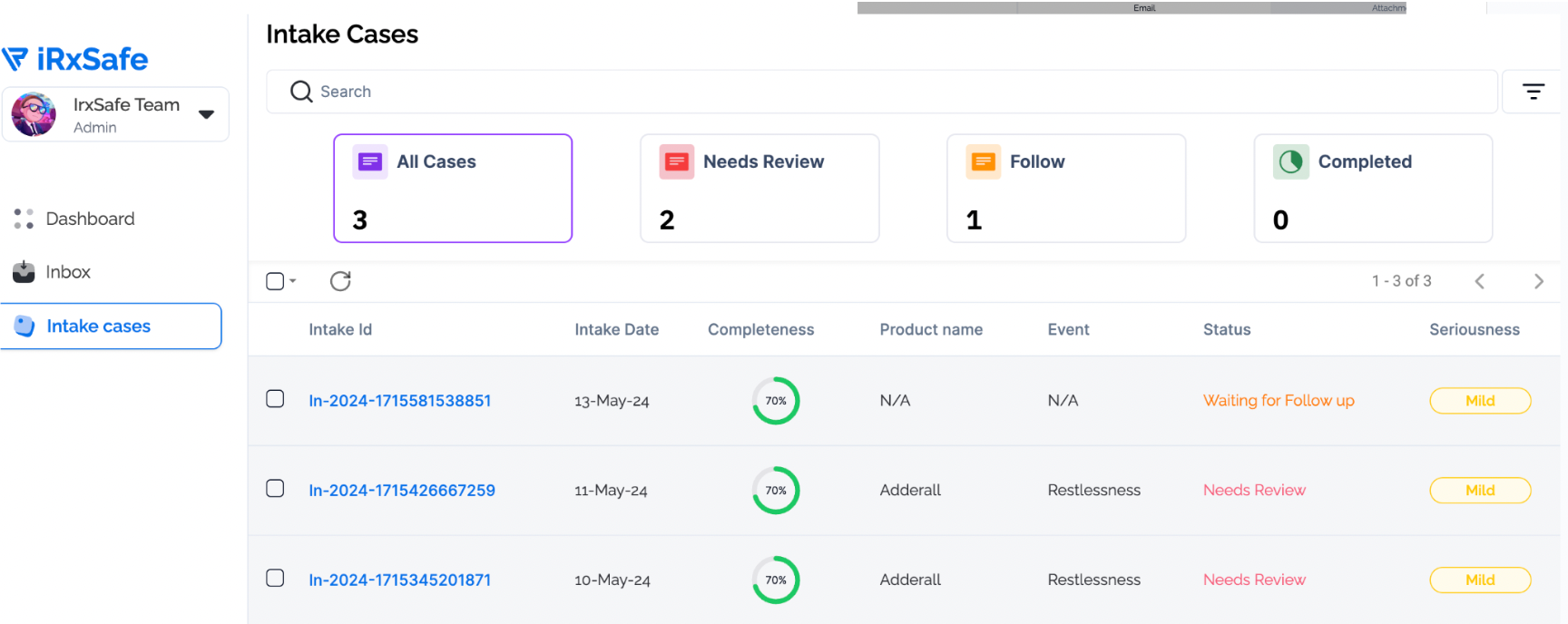
Fine-tuned Claude and GPT-3.5 language models on diverse medical report datasets including initial assessments, progress notes, evaluation reports, and specialized medical documents.
Achieved 95% classification accuracy through iterative training, validation, and optimization enabling reliable automated categorization of medical document types for medico-legal case processing.